Applicazione del drafting normativo e utilizzo di strumenti informatici / Stefano Bianchini*, Michele Visciarelli**
Numero 2 2025 • ANNO XLVI
* Funzionario presso il Gabinetto del Presidente dell’Assemblea legislativa della Regione Emilia-Romagna ** HPC Data Engineer/Machine Learning Engineer presso CINECA
1. Qualità “formale” e qualità “sostanziale” dei testi legislativi: due facce della stessa medaglia
«Una legge, e più in generale un atto normativo, è anzitutto (o anche) un documento fatto di parole»[1].
Da tale autorevole assunto è dato desumere come la qualità “formale” di un testo normativo – con particolare riguardo agli aspetti strutturali, sintattici, lessicali, grammaticali e finanche stilistici – rivesta un’importanza decisiva, in termini sia giuridici che politico - istituzionali, rispetto all’attività di produzione di norme.
Nonostante il ruolo fondamentale rivestito dalla qualità legislativa, nella produzione normativa nazionale e regionale si riscontrano, in letteratura[2] e nella prassi, diverse criticità redazionali che incidono negativamente sulla «missione di elaborare norme di qualità»[3], tra cui: i rinvii cd. “a catena”, che rendono quantomeno difficoltose l’interpretazione e l’applicazione delle norme; le disposizioni o i termini cd. «manifesto», che sono «scatole rivestite con i panni della legge»[4], prive o scarsamente dotate di un’effettiva capacità applicativa, quanto piuttosto preordinate a intercettare istanze di “visibilità politica”; la presentazione di emendamenti disomogenei e scollegati che spesso producono “obesità”[5] del testo; la formulazione di titoli delle leggi “muti” o comunque inconferenti con l’articolato, nonostante la loro rilevanza in termini di più immediata perimetrazione e inquadramento del complessivo intervento normativo; utilizzo di forme verbali o di termini desueti, o comunque poco comprensibile anche per gli addetti ai lavori; disomogeneità lessicale.
Oltre a tali profili patologici, sulla produzione normativa “di qualità” incide anche l’annoso fenomeno dell’ipertrofia normativa, distinto ma intimamente connesso alla qualità “formale” delle leggi, considerato che «una produzione legislativa impetuosa e disordinata conduce facilmente al sacrificio della qualità delle leggi»[6]; segnatamente, come rilevato da autorevole dottrina, «Le leggi vengono scritte troppo in fretta e il risultato sono disposizioni illeggibili, piene di rinvii a catena ad altre norme, poco conciliabili con quelle precedenti o perfino contraddittorie, che usano espressioni mai impiegate in precedenza, destinate a ingenerare incertezza e contenzioso, e spesso affermano principi e prescrizioni diversi da quelli che erano nell’intenzione di chi le ha scritte»[7].
Con specifico riferimento al contesto emiliano-romagnolo, come rilevato dal «Ventiduesimo Rapporto sulla legislazione della Regione Emilia-Romagna»[8], fino al 2000, la produzione media si è attesta intorno alle 40 leggi all’anno; dopo l’approvazione della riforma costituzionale del 2001, si è passati a una media di circa 25 leggi all’anno: con ciò, non appare comunque possibile sostenere sic et simpliciter l’equazione “meno leggi = maggior qualità”, un’equazione sbagliata se assunta in modo così assoluto. Se il numero di leggi può essere certamente significativo e indice di interventi settoriali fino alle cd. “leggi – provvedimento”, la qualità della produzione normativa passa anche attraverso altre valutazioni, attinenti alla forma – come sopra rilevato – ma anche al conseguente dato sostanziale, di raggiungimento degli obiettivi sottesi all’intervento legislativo.
Avendo più specifico riguardo al dato sostanziale, leggi poco chiare, contraddittorie, “asistematiche” (ossia avulse, parzialmente o completamente, dal contesto ordinamentale in cui sono chiamate ad operare) a causa delle citate criticità formali e della “frenesia” del Legislatore possono – infatti - determinare il mancato raggiungimento dei risultati perseguiti con la legge stessa, tradendo proprio le politiche e le finalità pubbliche ad essa sottese.
2. Qualità delle leggi e attività amministrativa
Le criticità qualitative, oltre che essere pregiudizievoli sotto i profili formale e sostanziale, possono determinare una disciplina «foriera di incertezza (…) che può tradursi in un cattivo esercizio delle funzioni affidate alla cura della Pubblica amministrazione»[9]. Su tale lunghezza d’onda, già nel 1979, nel «Rapporto sui principali problemi della Amministrazione dello Stato» (cd. “Rapporto Giannini”), si stigmatizzava la «pratica dei disegnini di legge per riparare ossicini fratturati o supposti tali», anche per evidenziarne i riflessi negativi rispetto all’esercizio dell’attività amministrativa.
Proprio la stretta e inevitabile connessione tra qualità legislativa ed esercizio delle funzioni amministrative che quelle leggi sono chiamate ad applicare – alla luce del noto principio di legalità – ha condotto la recente giurisprudenza costituzionale a censurare le norme «irrimediabilmente oscure»: segnatamente, secondo il Giudice delle leggi, «Con specifico riferimento a leggi regionali, infine, questa Corte (…) ha ritenuto censurabile, al metro dell’allora evocato parametro del buon andamento della pubblica amministrazione di cui all’art. 97 Cost., la tecnica normativa adottata, che rendeva difficilmente ricostruibile da parte dell’amministrazione la disciplina effettivamente vigente, giudicando tale tecnica «foriera di incertezza», posto che essa «può tradursi in cattivo esercizio delle funzioni affidate alla cura della pubblica amministrazione» (…). [D]eve più in generale ritenersi che disposizioni irrimediabilmente oscure, e pertanto foriere di intollerabile incertezza nella loro applicazione concreta, si pongano in contrasto con il canone di ragionevolezza della legge di cui all’art. 3 Cost.»[10].
In altri e più semplici termini, le norme “irrimediabilmente oscure”, oltre che elusive dei citati parametri e quindi passibili di incostituzionalità, si pongono in contrasto con la ragionevolezza e il buon andamento dell’azione amministrativa, nonché – in definitiva – con la stessa certezza del diritto poiché impediscono la corretta applicazione da parte della pubblica amministrazione e portano con sé il rischio di un aumento della cd. “burocrazia difensiva”, incrementano la conflittualità e il contenzioso (e non è un caso che una delle declinazioni del Progetto “SAVIA” attenga all’analisi e all’“incrocio” delle banche dati del contenzioso amministrativo), e precludono – in definitiva - la piena comprensibilità delle regole da parte della collettività.
Proprio sotto quest’ultimo profilo, con specifico riferimento all’assetto ordinamentale della Regione Emilia-Romagna, è da ricordare quanto prescritto dal comma 2 dell’art. 14 dello Statuto regionale, secondo cui la Regione riconosce, favorisce e promuove il diritto all’informazione sull’attività legislativa regionale, oltre che politica ed amministrativa, diritto la cui effettività presuppone la comprensibilità dei testi normativi di produzione regionale.
3. Il “Manuale di drafting”
Le considerazioni suesposte assumono ancora maggior rilevanza all’indomani della definizione della quarta edizione del “Manuale” recante «Regole e suggerimenti per la redazione dei testi normativi per le Regioni» (cd. “Manuale di drafting”), promosso dalla Conferenza dei Presidenti delle Assemblee legislative delle Regioni e delle Province autonome, con il supporto scientifico dell’Osservatorio Legislativo Interregionale (OLI), che rappresenta, un documento di tecnica legislativa (o cd. “drafting”), che – come noto – hanno come oggetto e scopo proprio «la buona redazione del testo, la migliore possibile nelle condizioni date»[11].
Più in particolare, il valore aggiunto della nuova versione del citato “Manuale” è rappresentato dal sottolineare e dall’enfatizzare il collegamento tra drafting “formale” e drafting “sostanziale”, dato che «Per la prima volta (…) a livello nazionale un manuale «istituzionale» sulla tecnica redazionale delle leggi accoglie e valorizza al proprio interno anche le tecniche sulla fattibilità dell’atto nel suo ciclo di vita: i processi valutativi e consultivi, gli strumenti per più una efficace comunicazione legislativa, le soluzioni per supportare la fase attuativa della legge»[12]. In particolare, il drafting “sostanziale” risulta sotteso alle cinque nuove “Appendici” del “Manuale”, concernenti, infatti: «La valutazione degli impatti della legislazione regionale», «Le consultazioni pubbliche», l’«Impiego di strumenti informatici per migliorare la qualità del testo normativo», la «Comunicazione istituzionale pubblica», le «Clausole formative»[13].
Per quanto specificamente rileva in tal sede, l’“Appendice” dedicata all’impiego di strumenti informatici, per vero già presente anche nell’edizione 2007 del “Manuale”, è stata arricchita anche con i possibili usi dell’intelligenza artificiale (IA) a supporto della decisione legislativa, finanche a prospettare «di utilizzare una funzione generativa di intelligenza artificiale per ideare o abbozzare un testo di natura normativa, che può in seguito essere utilizzato dagli esperti per render più breve il processo di redazione di un qualsiasi atto, purché a valle di questo processo artificiale di redazione normativa resti ferma valutazione finale dell’intelligenza umana»[14].
È pur vero che la declinazione operativa delle indicazioni contenute nel “Manuale di drafting” e l’applicazione degli strumenti di intelligenza artificiale ai procedimenti legislativi impongono riflessioni, oltre che sulla metodologia di lavoro, anche – e più in generale - sull’organizzazione stessa quale «momento fondamentale dell’amministrazione»[15], ripensando l’organico degli uffici legislativi, da integrare con professionalità informatiche, potenziando la formazione del personale già assegnato e valorizzando la “cultura della qualità delle leggi”.
4. Gli “indicatori di qualità formale” elaborati nell’ambito del progetto “SAVIA”
Gli strumenti di elaborazione del linguaggio naturale (Natural Language Processing, NLP) e di intelligenza artificiale (IA) trovano oggi un impiego sempre più ampio in numerosi ambiti, tra cui l’estrazione automatica di informazioni da testi digitalizzati, l’analisi del sentiment e la categorizzazione tematica dei documenti. Questi strumenti, applicati all’analisi testuale, offrono vantaggi significativi su più livelli. Da una prospettiva generale, le tecniche di NLP e IA consentono di automatizzare processi analitici, migliorare l’accuratezza nell’identificazione delle informazioni e ridurre i tempi di lavoro, supportando così l’attività degli utenti con maggiore efficienza. Dal punto di vista specificamente giuridico, tali strumenti si rivelano preziosi per favorire la comprensione del contesto normativo entro cui una disposizione opera e per fornire supporto decisionale basato sui dati estratti dai testi normativi. In questo modo, il ricorso a strumenti avanzati di analisi automatica non solo velocizza i processi di interpretazione delle norme, ma offre anche una base solida per valutazioni più informate e basate sui dati.
Proprio al fine di declinare l’applicazione di strumenti di intelligenza artificiale e di natural language processing nell’ambito della produzione legislativa regionale con specifico riguardo al drafting, nell’ambito del Progetto “SAVIA”, sono stati individuati “indicatori di qualità” che, sulla base di dati testuali, consentono un’analisi e una valutazione della qualità formale del testo legislativo, anche al fine di restituire un report a supporto, tra l’altro, degli organi regionali nonché del lavoro dei tecnici per migliorare la qualità delle leggi.
Più in particolare, si tratta di indicatori di carattere testuale tra cui il numero di parole e la loro lunghezza, la complessità delle frasi, l’utilizzo di verbi diversi dall’indicativo presente e soprattutto l’utilizzo di gerundi, di verbi modali e in forma passiva, il numero di riferimenti “a catena” ad altre leggi, l’inserimento – a seguito di modifiche legislative successive - di articoli o commi che recano l’elencazione bis, ter, quater e seguenti: il riscontro di tali indicatori consente di effettuare una (prima) valutazione in ordine alla “tenuta” formale della legge, in coerenza con l’obiettivo di «rafforzare e valorizzare la funzione legislativa» (art. 31, comma 1, dello Statuto regionale).
L’analisi del testo attraverso questi indicatori testuali parte da testi normativi digitalizzati, per questa applicazione prelevati dal database Demetra, successivamente convertiti in un’unica stringa di testo. Questa stringa, rappresentante il contenuto completo delle leggi regionali, costituisce il dato fondamentale per l’analisi automatizzata.
Il processo prevede l’applicazione di tecniche specifiche tramite librerie software specializzate:
- lemmatizzazione: riduzione delle parole alla loro forma base (lemma), come trasformare “correva” in “correre”;
- stemmazione: riduzione delle parole alla loro radice comune, utile per riconoscere varianti lessicali simili (es. “correre” e “corso”);
- tokenizzazione: suddivisione del testo in unità minime (token), solitamente parole o frasi.
L’output è una rappresentazione astratta della legge, contenente tutte le parole ripulite e ridotte alle loro unità fondamentali, assieme alle parole originali come riferimento. Sono state quindi scritte librerie specifiche per il riconoscimento di gerundi, verbi passivi e verbi modali attraverso il riconoscimento di pattern linguistici specifici (ad esempio le tipiche desinenze che caratterizzano i verbi al gerundio). Al termine di tutti questi passaggi, è stato creato un dataset contenente il testo originale della legge e associata ad essa tutti gli indicatori definiti precedentemente, in aggiunta a tutta una serie di metadati come la vigenza e la data di entrata in vigore.
Avere a disposizione un dataset completo aumentato con metadati riguardanti le leggi in esame permette di effettuare analisi, in particolare su serie temporali, ossia l’andamento di un indicatore nel tempo. Per ciascun indicatore analizzato, come il numero di gerundi o la lunghezza media delle frasi, si possono ad esempio costruire grafici dell’andamento medio, ovvero rappresentazioni della media dell’indicatore per tutte le leggi emanate in un anno, e confrontare una legge in esame con la media, ovvero definire il suo posizionamento rispetto alla media storica e annuale.
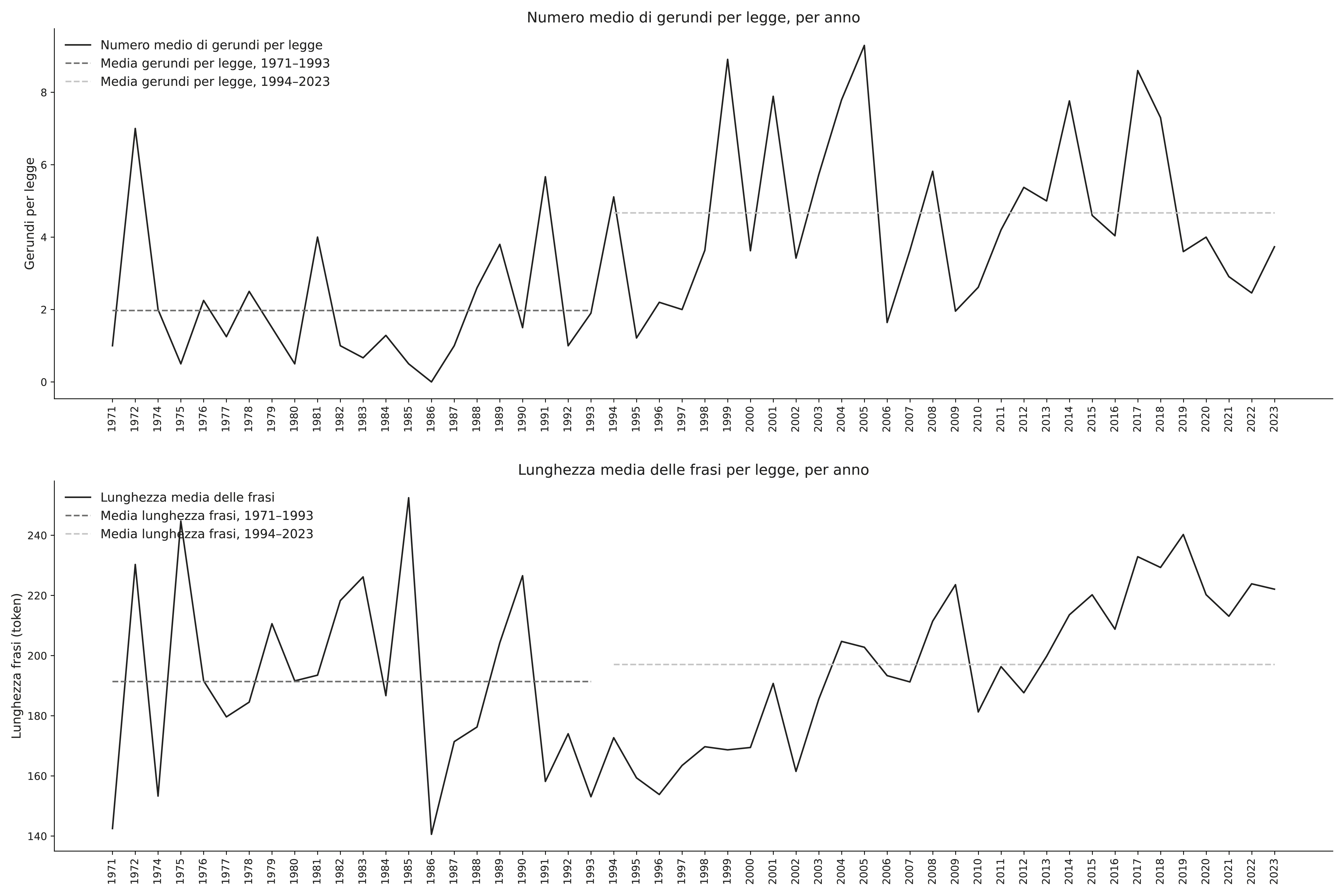
Figura 1. Esempio di serie temporale per il numero di gerundi (in alto) e lunghezza media delle frasi (in basso). Queste metriche sono state calcolate per tutte le leggi nel database Demetra, poi suddivise e mediate per anno. Viene anche riportato un esempio di possibile analisi temporale: variazione della metrica rispetto a finestre temporali predefinite
Questa analisi visiva fornisce già un’indicazione qualitativa: se una legge mostra valori significativamente superiori alla media (ad esempio, un uso eccessivo di gerundi o frasi lunghe), potrebbe indicare scarsa qualità testuale. Inoltre, è possibile effettuare analisi statistiche sugli indicatori suddividendo le leggi per tipologia, ad esempio andando a sottolineare le diverse distribuzioni degli indicatori in testi coordinati e in leggi ordinarie.
A partire dagli indicatori definiti e calcolati, è naturale considerare la possibilità di costruire un indicatore aggregato, ovvero un unico valore che sintetizzi le informazioni provenienti dai diversi parametri di analisi della qualità testuale. Questo approccio permette di ottenere uno score facilmente interpretabile e immediatamente utilizzabile per valutare il livello di qualità normativa di un testo legislativo.
Lo score integrato si basa su un principio semplice: in generale, valori più bassi degli indicatori corrispondono a una maggiore qualità testuale. Ad esempio, testi con un minor utilizzo di gerundi, frasi più concise e una struttura sintattica più chiara tendono a essere più leggibili ed efficaci. Per costruire questo score, è stato definito un algoritmo che segue i seguenti passaggi:
- eliminazione delle variabili ridondanti: vengono rimosse le variabili correlate per evitare ridondanze nell’analisi. Si utilizza lo stesso dataset già impiegato in precedenza;
- calcolo di una misura sintetica per ogni legge: viene applicata una misura detta “norma L1”, che consiste nella somma dei valori assoluti di tutte le caratteristiche testuali analizzate. In genere, più questo valore è piccolo, più significa che nella maggior parte degli indicatori la legge aveva un valore piccolo. Come già menzionato, assumiamo che il target per una legge sia quello di avere questa “norma L1” più piccola possibile (quindi meno gerundi utilizzati possibili, frasi il più corte possibili, eccetera);
- normalizzazione dei valori: i punteggi calcolati vengono scalati su una scala da 0 a 1 per garantire omogeneità tra i valori associati ai testi;
- ordinamento delle leggi: i testi normativi vengono disposti in ordine crescente rispetto al valore della norma L1 calcolata;
- segmentazione in cinque fasce: le leggi vengono suddivise in cinque categorie basate sul punteggio ottenuto;
- attribuzione di un giudizio qualitativo: a ogni fascia viene assegnato un valore da 1 (migliore qualità testuale) a 5 (peggiore qualità testuale), fornendo così un riferimento chiaro e sintetico per la valutazione.
Questo metodo, che consente di ottenere una misura oggettiva della qualità linguistica di un testo normativo, facilitando sia l’analisi ex post delle leggi esistenti sia la redazione di nuovi testi legislativi con criteri di maggiore chiarezza e leggibilità, è quindi stato applicato alle leggi attualmente vigenti ed è estendibile in maniera naturale a leggi che verranno approvate in futuro. Il calcolo e la fruizione di queste metriche verranno direttamente integrati nel chatbot “SAVIA”, attraverso una dashboard con grafici relativi alle serie storiche, al posizionamento della legge in esame rispetto alle serie storiche e il valore dello score integrato.
Sul presupposto della citata relazione che intercorre tra qualità della legislazione e attività amministrativa, il progetto “SAVIA” si è proposto anche di attuare un collegamento tra le leggi regionali stesse e le pronunce del giudice amministrativo (T.A.R. Emilia-Romagna e Consiglio di Stato) aventi ad oggetto atti amministrativi che trovano nelle citate leggi la propria “copertura” normativa, al fine di valutare quanto l’(eventuale) illegittimità dell’atto sia dipesa da una criticità della legge medesima.
Analizzando i database disponibili delle pronunce[16], emerge che tale collegamento non è immediatamente evidente: esso non è esplicitamente indicato né nei testi delle sentenze né all’interno delle banche dati stesse, risultando quindi non estraibile attraverso tecniche standard di web scraping. In genere, il collegamento tra sentenza e legge di riferimento avviene attraverso due passaggi: il primo, dalla sentenza all’atto amministrativo impugnato; il secondo, dall’atto alla legge regionale su cui esso si fonda.
Attualmente, i dati relativi al secondo passaggio, ossia il collegamento tra atti amministrativi e leggi regionali, sono già stati ricavati nell’ambito della creazione dei metadati legislativi per altre applicazioni del progetto “SAVIA”. Tuttavia, resta da colmare la lacuna relativa al primo passaggio, ovvero l’individuazione sistematica degli atti amministrativi richiamati all’interno delle pronunce giurisdizionali.
Un’ulteriore carenza riguarda l’assenza di un sistema efficace per la categorizzazione delle pronunce secondo i relativi esiti processuali. Tale categorizzazione è essenziale per sviluppare indicatori capaci di misurare la qualità formale delle leggi, valutandone anche la “resistenza” rispetto al rischio di ricorsi e contenziosi amministrativi.
Per affrontare il primo problema, ovvero l’estrazione degli atti menzionati nelle sentenze, il progetto fa ricorso a metodi di intelligenza artificiale, con particolare attenzione all’impiego di modelli linguistici avanzati (Large Language Models, LLM). Questi ultimi, grazie alle loro capacità di analisi del linguaggio naturale, consentono di eseguire un’analisi approfondita del testo delle pronunce, identificando in modo sistematico riferimenti ad atti, determinazioni, deliberazioni e provvedimenti simili. L’evoluzione degli LLM di ultima generazione offre inoltre un vantaggio significativo: rende superflua la costosa fase di fine-tuning (ovvero l’addestramento specifico su un corpus di testi giuridici), permettendo invece di ottenere risultati efficaci tramite il solo prompt engineering. Questa tecnica consiste nella formulazione accurata di istruzioni e nell’inclusione di esempi specifici per guidare il modello nell’analisi testuale. I modelli più moderni, infatti, sono in grado di eseguire complesse operazioni di analisi e ragionamento testuale anche quando affrontano istruzioni nuove o contesti non espressamente previsti durante il loro addestramento. Dopo aver passato l’intero dataset delle sentenze attraverso un LLM con un opportuno prompt, otteniamo quindi un dataset “aumentato”: testo delle sentenze e tutti i riferimenti ad atti amministrativi nel suddetto testo. A questo punto è quindi semplice passare da sentenza, ad atto regionale, a legge regionale di riferimento.
Riguardo al secondo problema, ovvero la categorizzazione delle pronunce secondo i relativi esiti processuali, viene ancora una volta in aiuto il testo delle pronunce stesse: il testo presenta infatti aree altamente strutturate. In particolare, l’“esito” è cristallizzato nel dispositivo (il “P.Q.M.”), che possiamo separare ed analizzare indipendentemente. Inoltre, gli esiti sono sempre all’interno di un certo numero di possibilità rappresentate da keyword facilmente estraibili (ad esempio, “respinto”, “accolto”, “improcedibile”, eccetera) con semplici metodi di pattern recognition testule.
Per affrontare questo compito, è possibile impiegare sistemi di Named Entity Recognition (NER) basati su un approccio Zero-Shot. Questo approccio consente di definire dall’esterno le categorie di dati da ricercare senza la necessità di un addestramento specifico su un dataset giuridico: il modello può identificare e classificare automaticamente le entità testuali pertinenti, come gli esiti processuali, attraverso istruzioni testuali (prompt) e semplici esempi.
L’analisi sperimentale, condotta su un campione di 200 sentenze, ha evidenziato che il sistema di classificazione Zero-Shot identifica correttamente l’esito processuale nel 75% dei casi. Tuttavia, l’analisi degli errori ha rivelato una criticità specifica: la maggior parte degli errori riguarda la distinzione tra le classi “improcedibile” e “inammissibile”. Sebbene queste due categorie abbiano significati giuridicamente distinti, dal punto di vista algoritmico esse risultano difficili da differenziare, poiché il loro contesto testuale è simile e le formule utilizzate nei provvedimenti spesso presentano espressioni sovrapponibili.
Per risolvere questa difficoltà e ottenere una valutazione più funzionale ai fini dell’analisi della qualità legislativa, è possibile semplificare la classificazione raggruppando gli esiti processuali in due macro-categorie principali: ricorso “negativo” per il legislatore, che comprende i casi in cui il ricorso viene accolto, anche parzialmente, a favore del ricorrente, e ricorso “positivo” per il legislatore, che include tutte le situazioni in cui il ricorso viene dichiarato inammissibile, improcedibile, o si verifica una cessazione della materia del contendere (ad esempio, per rinuncia all’interesse da parte del ricorrente).
Questa semplificazione, che riduce le categorie a due sole classi (“positivo” e “negativo”), permette al sistema di classificazione di ottenere un’accuratezza complessiva del 97%. Tale miglioramento dimostra l’efficacia di una categorizzazione mirata e adattata agli obiettivi del progetto, garantendo una misura più affidabile della qualità normativa in relazione al contenzioso generato.
5. Conclusioni
La qualità formale delle leggi è strettamente connessa sia all’efficacia sostanziale dell’azione legislativa sia al corretto esercizio delle funzioni amministrative: l’importanza di testi chiari, coerenti e leggibili garantiscono certezza del diritto e buon andamento della pubblica amministrazione.
Il progetto SAVIA emerge come un esempio concreto di applicazione delle nuove tecnologie al servizio della qualità legislativa. In particolare, l’uso di strumenti di Natural Language Processing (NLP) e Large Language Models (LLM) ha permesso di definire e applicare indicatori oggettivi per la valutazione della qualità formale dei testi normativi, analizzando aspetti quali lunghezza delle frasi, uso dei gerundi, verbi passivi e rinvii normativi a catena. Questa analisi sistematica, integrata con metadati e serie storiche, consente di confrontare i testi legislativi con le medie storiche e identificare potenziali criticità nella redazione.
Il progetto ha affrontato altre due sfide specifiche. La prima riguarda l’individuazione dei collegamenti tra sentenze e leggi. Attraverso l’uso di LLM con tecniche di prompt engineering, è stato possibile estrarre automaticamente riferimenti ad atti amministrativi dai testi delle pronunce giurisdizionali, colmando così una lacuna informativa essenziale per analizzare l’impatto delle leggi sui contenziosi amministrativi. La seconda sfida riguarda la categorizzazione automatica degli esiti processuali. Mediante l’impiego di sistemi di Named Entity Recognition (NER) in modalità Zero-Shot, il progetto ha raggiunto un’accuratezza del 97% nel distinguere esiti favorevoli o sfavorevoli per il legislatore, fornendo così uno strumento prezioso per misurare la “robustezza” delle leggi rispetto al rischio di ricorsi.
Queste innovazioni, oltre a dimostrare l’efficacia dell’integrazione tra competenze giuridiche e tecnologie avanzate, segnano un passo significativo verso un miglioramento strutturale del processo legislativo. L’esperienza del progetto SAVIA sottolinea inoltre l’importanza di investire nella formazione delle professionalità coinvolte, promuovendo una “cultura della qualità delle leggi” che sappia coniugare tecnica redazionale, analisi dei dati e uso responsabile dell’intelligenza artificiale.
È di interesse notare anche che non è sempre stato necessario utilizzare la tecnologia più recente o più avanzata disponibile. Gran parte del lavoro effettuato è stato basato su tecniche NLP definite “classiche”, se non addirittura su semplici riconoscimenti di pattern nei testi. Questo dimostra l’esistenza di un grande spazio ancora inesplorato di possibili convergenze fra il mondo giuridico e quello informatico.
Note
[1] Così G.U. Rescigno, Tecnica legislativa (voce), in Enc. giur. Treccani, XLI, Roma, 1993, p. 1.
[2] Senza pretesa di esaustività, si ricordano: M. Ainis, Il linguaggio della legge tra inflazione e inquadramento legislativo, in Diritto e formazione, 2002, pp. 1809-1815; M. De Benedetto, M. Martelli, N. Rangone, La qualità delle regole, Bologna, 2011; U. De Siervo, Cosa si intende per leggi “mal scritte”?, in P. Caretti, M.C. Grisolia (a cura di), Lo Stato costituzionale. La dimensione nazionale e la prospettiva internazionale. Scritti in onore di Enzo Cheli, Bologna, 2010, pp. 279-294; L. Di Majo, La qualità della legislazione tra regole e garanzie, Napoli, 2019; G. Falcon, La “tecnica legislativa” nelle leggi regionali, in S. BARTOLE (a cura di), Lezioni di tecnica legislativa, Padova, 1988, pp. 173-186; G.U. Rescigno, L’errore materiale del legislatore, la cattiva redazione delle leggi e la Corte, in Giur. cost., 3, 1992, pp. 2418-2428; Id., Le tecniche legislative in Italia, in C. Biagioli, P. Mercatali, G. Sartor (a cura di), Legimatica: informatica per legiferare, Napoli, 1995, pp. 17-34.
[3] L’espressione è mutuata da F. Vassalli, La missione del giurista nella elaborazione delle leggi, in JUS, 3-4, 1950, pp. 309-321.
[4] Così M. Ainis, La legge oscura. Come e perché non funziona, Roma – Bari, 1997, p. 14.
[5] La locuzione è mutuata da S. Ceccanti, Decreti obesi e crisi economica, ovvero la vittoria strisciante dell’assemblearismo, in Quad. cost., 1, 2014, pp. 109-159.
[6] Così B.G. Mattarella, La trappola delle leggi. Molte, oscure, complicate, Bologna, 2011, p. 79.
[7] Ibidem, p. 80.
[8] Le diverse edizioni del rapporto sulla legislazione della Regione Emilia-Romagna, dal 2000 ad oggi, sono consultabili e scaricabili in regime di open access
[9] In questi termini, v. le pronunce della Corte cost.16 aprile 2013, n. 70; 22 dicembre 2010, n. 364. Sia consentito rinviare anche a S. Bianchini, La funzione normativa del Consiglio regionale, in M. Belletti, F. Mastragostino, L. Mezzetti (a cura di), Lineamenti di diritto costituzionale della Regione Emilia-Romagna, Torino, 2016, pp. 120-123, in cui si evidenzia i profili di stretta interdipendenza tra qualità “formale” e qualità “sostanziale” esaminando gli istituti di verifica ex ante e controllo ex post previsti dallo “Statuto della Regione Emilia-Romagna” (L.R. 31 marzo 2005, n. 13) e dal “Regolamento interno dell’Assemblea legislativa dell’Emilia-Romagna” (delibera dell’Assemblea legislativa 28 novembre 2007, n. 143). Più in generale, v. T. Giupponi, F. Caruso, Qualità della legislazione e valutazione delle politiche pubbliche: le clausole valutative in alcune esperienze regionali, in questa Rivista, Quaderno 1, 2011, pp. 39-56.
[10] Così Corte cost., 5 giugno 2023, n. 110.
[11] G.U. Rescigno, Tecnica legislativa (voce), op. cit., p. 1.
[12] In questi termini M. Pietrangelo, Un nuovo approccio metodologico nel Manuale per la redazione delle leggi regionali: riannodare il drafting formale e il drafting sostanziale, in Consulta Online, II, 2024, p. 937.
[13] Cfr. “Manuale di drafting”, pp. 145-182.
[14] Cfr. “Manuale di drafting”, p. 168.
[15] L’espressione è di G. Berti, La pubblica amministrazione come organizzazione, Padova, 1968, p. 66.
[16] Ossi https://www.giustizia-amministrativa.it/.
Parole chiave: qualità legislativa; leggi oscure; redazione di atti legislativi; emendamenti; indici di qualità legislativa
Keywords: Legislative Quality; Obscure Laws; Drafting of Legislative Acts; Amendments; Legislative Quality Indices